지도학습에서 모델을 학습시키고 이 모델의 분류 성능을 평가하기 위해 분류 성능 지표를 사용한다.
1. confusion matrix
지도 학습으로 훈련된 분류 알고리즘의 성능을 시각화할 수 있는 표.
모델이 예측한 값과 실제 값이 어떻게 일치하는지 볼 수 있다.

- TP : 실제 Positive를 Positive라고 정확하게 분류한 개수
- FP : 실제 Negative를 Positive라고 잘못 분류한 개수
- FN : 실제 Positive를 Negative라고 잘못 분류한 개수
- TN : 실제 Negative를 Negative라고 정확하게 분류한 개수
T/F는 예측이 맞았는지를 나타내고, P/N은 예측한 레이블을 나타냅니다. 이 구성을 기억하면 더 쉽게 이해할 수 있습니다.
2. Recall과 Precision
recall과 precision은 분류 성능을 평가하는 지표들 중 일부입니다.

- Precision (정밀도): 모델이 Positive라고 예측한 것 중 실제로 Positive인 것의 비율을 나타냅니다. 즉, 모델이 예측한 Positive가 얼마나 정확한지 확인할 수 있습니다.
- Recall (재현율): 실제 Positive 중에서 Positive로 정확하게 예측한 비율을 나타냅니다. 즉, 실제 Positive 샘플을 모델이 얼마나 잘 찾아냈는지를 평가합니다.
3. Precision과 Recall의 관계
Precision과 Recall 서로 trade-off 관계 입니다.
Precison은 FP를 줄이는 것에 집중하고
Recall은 FN 을 줄이는 것에 집중합니다.
모델을 훈련시키고 테스트 데이터로 평가할 때 threshold를 설정합니다. 이 threshold를 변화시키면 precision과 recall은 서로 영향을 주고 받게 됩니다.
.
예시 1: threshold = 0
threshold를 0로 설정하면 모델은 모든 예측 Positive로 하게 됩니다.
False Positive (FP)가 늘어나고, False Negative (FN)는 줄어듭니다 . 즉, Precision이 낮아지고 Recall은 높아집니다..
예시 2: threshold = 1
반대로, threshold를 1로 설정하면 모델은 모든 예측을 Negative로 하게 됩니다.
이 경우, False Negative(FN)은 증가하고 FP 는 줄어듭니다. 즉, Precision은 높아지고 Recall은 낮아집니다.
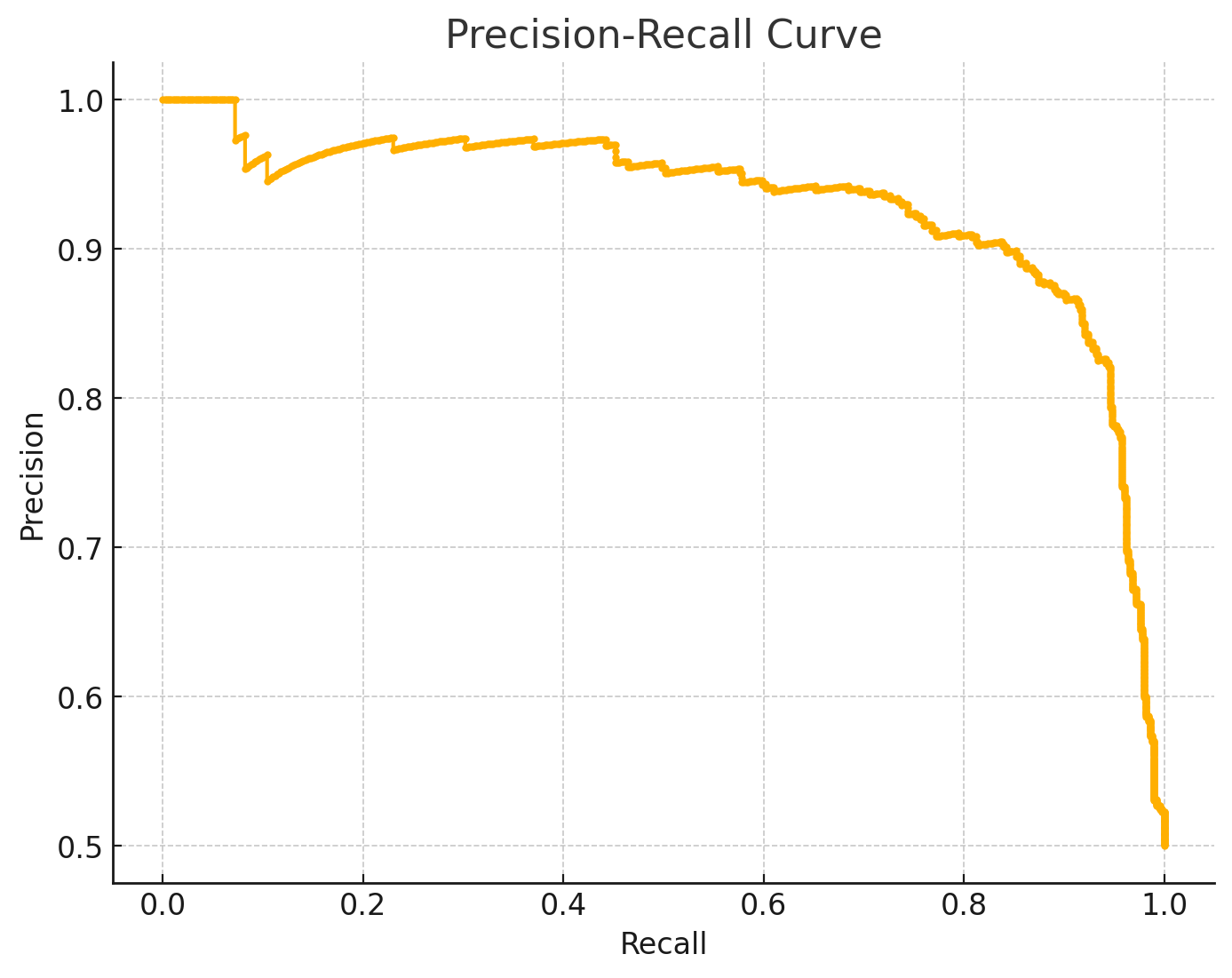
4. PR curve
0부터 1사이의 모든 임계값에 따라 x축을 recall, y축을 precision 로 그린 그래프입니다. recall과 precision 모두 높을 수록 좋은 모델입니다.
reference
https://ko.wikipedia.org/wiki/%ED%98%BC%EB%8F%99_%ED%96%89%EB%A0%AC
혼동 행렬 - 위키백과, 우리 모두의 백과사전
위키백과, 우리 모두의 백과사전. 기계 학습 분야의 통계적 분류 같은 문제에서 혼동 행렬(Confusion matrix)[1] 이란 지도 학습으로 훈련된 분류 알고리즘의 성능을 시각화 할 수 있는 표이다. 행렬의
ko.wikipedia.org
모델 평가하기 - 정확도만 높으면 좋은 모델?
* 카테고리 별로 읽기보다, 글 순서대로 읽는걸 추천드려요. 순서 정확도의 문제 재현율, 정밀도 F score 임계값 조절 PR curve vs ROC curve Confusion Matrix 1. 정확도의 문제 모델 성능을 비교할 때 그리고
hwi-doc.tistory.com